The new version of the HTML Import plugin is just about done. It’s completely rewritten and has several big new features:
It imports linked images. (OMG, I KNOW.) It can handle all of the following paths, as long as they lead to actual image files:
<img src=”http://example.com/images/foo.jpg” />
<img src=”/images/foo.jpg” />
<img src=”../../images/foo.jpg” />
<img src=”foo.jpg” />
Using custom post types? The importer now has options to import posts as any public post type. This means the plugin now requires at least WordPress 3.0.
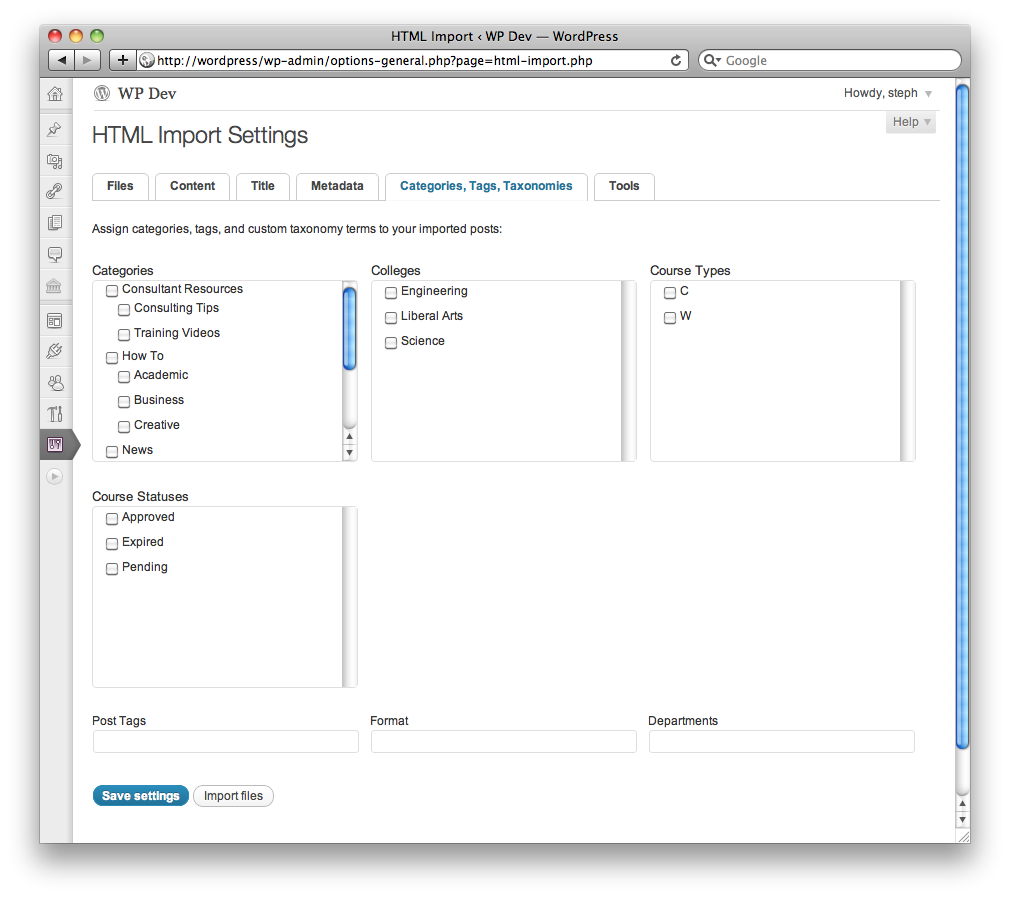
It has supported custom taxonomies for several versions now, but in 2.0, the hierarchical ones (including categories) are displayed as nice little lists of checkboxes. Much nicer.
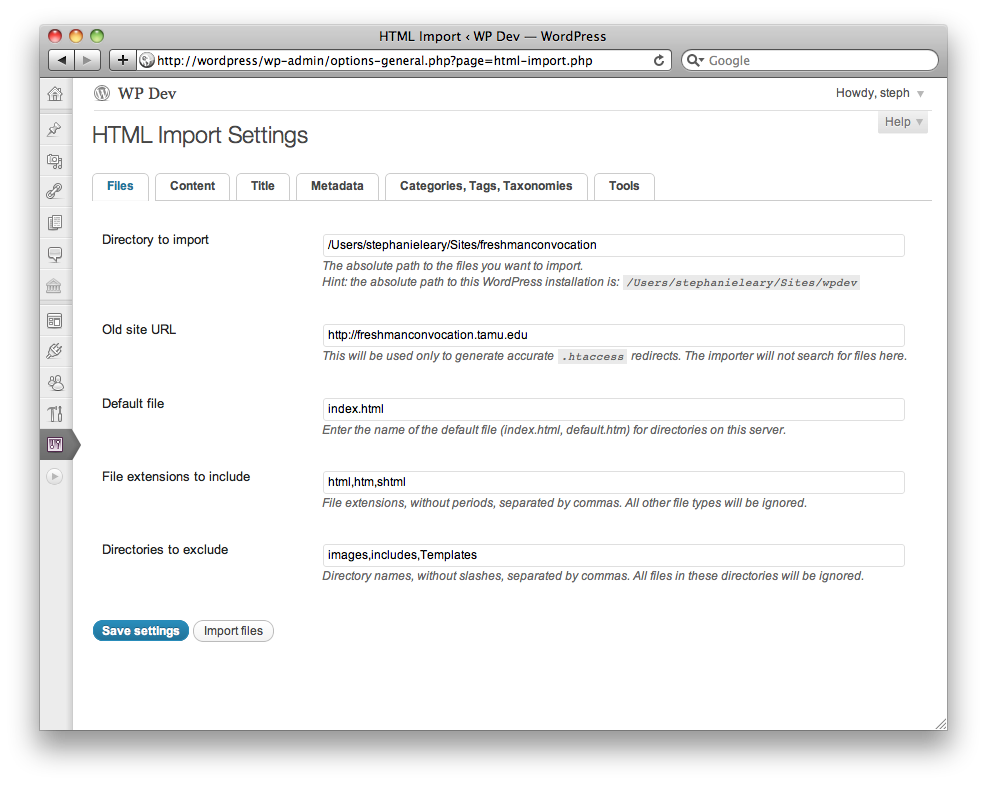
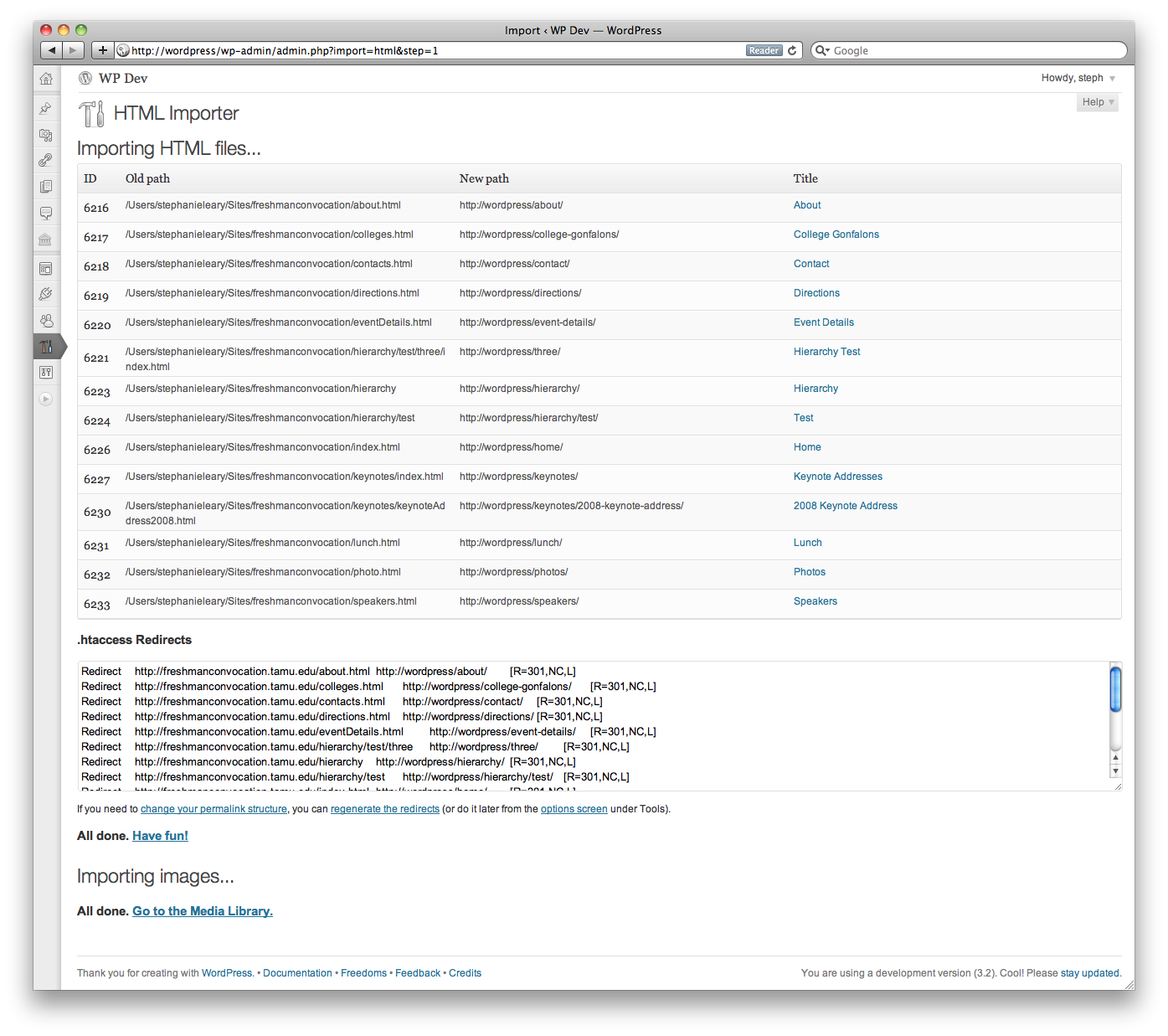
There’s now an option to enter your old site URL, which will be used to generate accurate .htaccess redirects. You can also retrieve the redirects again later if you need to, or regenerate them after you’ve changed your permalink setting, because the old URLs are now stored as custom fields of the imported posts.
The user interface is completely different. The settings have their own page, and the importer has been moved into Tools → Import. The settings that could make things go disastrously wrong, like a beginning directory path that doesn’t exist, will now trigger some error messages.
There’s a help tab on the settings page, and there’s a new User Guide (still in progress; please forgive the giant images).
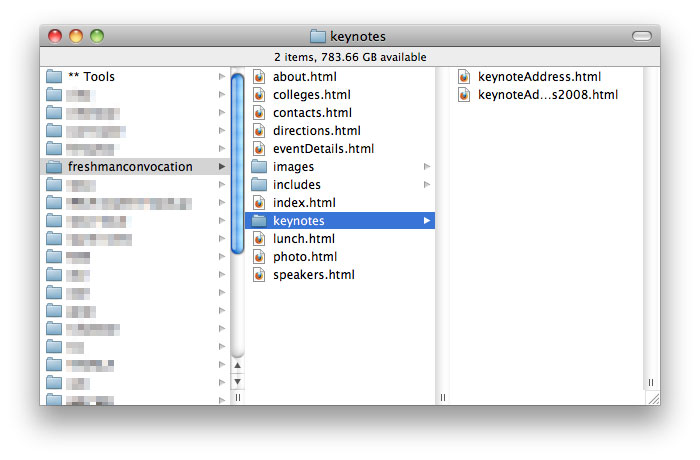
Last-minute feature addition: default/index files for parent pages! In the past, the importer created empty placeholder pages when it encountered a directory, and then it would import all the files in that directory as child pages. In 2.0, you can specify the name of your default/index file (usually index.html on Apache servers or default.htm on IIS), and the importer will replace the empty placeholder with the index file’s contents. If there is no index file, the parent page remains empty.
I need testers!
If you’re willing to try out the beta, grab the development version from the Download page.
Here’s what it looks like…






Awesome! I used your plugin in the past and am excited to seen an update to make it even better. :)
I tried it out today and the import is great. I love the new title feature that lets us remove certain parts from the title of each page.
I am having some problems getting the image upload to work. It seems to be working for about 15 items, but not working for all the rest (300 or so pics). This is the error I am getting is similar to this:
Could not find the right path to 4277d749212993f5293f6d71b08ea732.jpg (tried /Users/jeffvandrimmelen/Desktop/exss/files/cache/4277d749212993f5293f6d71b08ea732.jpg). It could not be imported. Please upload it manually.
I am using MAMP on a local machine. I scraped the live site to test this. The .jpg is certainly at that location. It shows up when navigating through Finder. It also shows up when browsing the html site locally: file:///Users/jeffvandrimmelen/Desktop/exss/exss.unc.edu/files/cache/4277d749212993f5293f6d71b08ea732.jpg
Maybe I am doing something wrong in the settings. Any thoughts you have would be appreciated. I am running wordpress 3.2 locally on a mac using MAMP.
Jeff, I’ve fixed all the bugs except the image path problem. What’s the live site you scraped for your test? I’d like to do the same.
I am also having a second problem that I’m not sure is connected to his, or if there is a workaround. If you look at this picture of the file structure of the site.
http://vanswebsites.com/uploads/2011-07-07_1457.png
You will see that there is a file that is about 4 levels deep, but because there are no index (or html) pages above that in the structure it put’s it as a top level page. Is there any way way to create the top levels? Do I need to add blank index.html pages to each folder to help keep the hierarchy?
For kicks I went back and installed version 1.3 and was able to get the hierarchy back from the folders, so I think this might be a bug with the new version.
Jeff, thanks for all this great detail! I’ll look at those issues this weekend.
Any luck with these things? If not, no worries. Just wanted to check with you before I start monkeying again. :)
Alas, not yet. I haven’t been feeling well, so I’ve been a couch potato for a few days.
Oh man, I’m so sorry. Feel better. I’m here to test when you are feeling up to to.
Exss.unc.edu.
I think it was a problem from the cms (concrete) I scraped from though.
Thanks! I’ll give it a shot anyway and see what’s going on.
Definitely not your CMS! I had a reeeeeally dumb typo. Embarrassingly stupid and obvious once I looked at it!
I just ran a perfect import on that site. Grab a fresh download — it should say it’s beta 3 — and see if all your problems are solved. :)
All — beta 3 is up, and fixes all the problems that have been reported here and on wordpress.org. I’m going to be out of town later this week, so I’m planning to release this on Monday. If you find any more issues in the meantime, please feel free to report them here, or you can try out the shiny new support forum!
Thanks for all your help! You’ve found some great (embarrassing) bugs.
Great. Thanks for this awesome plugin Stephanie. I don’t have time to test this now, but will certainly be testing it in the future! :)
Hi,
When I am trying to import the html page containing image using HTML import 2 plug-in, html content is imported but image is not imported to the media library.
Done all the settings given in the user guide for the plug-in.
Image import gives the following error
“Could not find the right path to sample.jpg (tried /Users/savitha/Sites/savitha/sample.jpg). It could not be imported. Please upload it manually.”
Given proper path for the image in the html.
Can you please give inputs where I am missing steps.
Thanks in advance.
Hi Stephanie, thanks for creating this fantastic plugin !!
I´m kiku from Spain, and i have a big problem;
(Before importing) my post titles and permalinks are;
¿Y Tú CóMO ORDENAS LOS PAPELES DE OTROS AñOS? (2 PARTE)
http://www.mydomain.com/y-t-cmo-ordenas-los-papeles-de-otros-aos-2-parte/index.html
(permalink eliminated characters including accents)
When importing with plugin HTML Import 2.0 … The result is;
¿Y Tú CóMO ORDENAS LOS PAPELES DE OTROS AñOS? (2 PARTE) (is perfect)
but the permalink …
http://www.mydomain.com/y-tu-como-ordenas-los-papeles-de-otros-anos-2-parte/index.html
Characters with accents were replaced by letters :(
¿ this big problem is caused by your plugin, or new versions of wordpress?
¿ know how I can fix ?
Thank you very much and happy life for you and your family :)
Kiku, I’m pretty sure that’s how WordPress handles all accented characters in URLs. :(
I’m excited to see such a robust import tool for WordPress. Thank you for creating this plugin and making it available. I downloaded the beta and tried out the slug — works well.
I have a few questions. Is there any way to make the new import simply overwrite the existing files? Or do you have to first delete the old pages completely before importing a new set of files? I ask because I want to use WordPress as a help platform, but I want to author content in another tool and continually run an import process into WordPress.
Thanks,
Tom
My import of over 700+ pages worked wonderfully, but for some reason when the imported pages show up in the WordPress “search results”, the content excerpt is always displayed simply as the text “Array”. However, if I copy one of those pages’ HTML from within the editor and past it into a new page that I manually add, that same content is able to display just fine in the “search result” content excerpt. Any ideas what might be the difference between the “HTML Import 2” created page versus a native WordPress one? Thanks for creating such a powerful plugin!
I just noticed that bug on an import I’m working on. I’ll have it fixed shortly.
(BTW, the support forum is a much better place for questions.)
Allan, I’ve just learned that PHP’s SimpleXML library is case-sensitive. In my test site, the excerpts failed because the meta tags were written like this:
meta name="Description". Could that be the problem on your site as well?i have installed your bluing but i can’t work with it so if you please upload a video of your plugin so every one can understand how it’s work and if you have already one can you please send the link please .
My pages are all php with a php variable in the code called “$content_title”. I’d like to be able to pull the value of $content_title into the title.
Any thoughts on how I can do that with this plugin? or does there need to be a field or programming put in to your plugin to get that to work?
We are converting our old web site of about 3700 pages to WordPress. I have written a program to strip out all of the old included information, etc. Once the files are “clean” I am sending them through your program to import them into WordPress. The only tags I am leaving in the files are html, title, strong, br , p, meta text, head, body, div id=main, doctype, and rel.
When I attempt to input a large amount of files, the program seems to “hang”. In actuality, the program errors and exits with no clue as to what the problem is. The message in the apache error log is: “[Sat Dec 29 10:56:21 2012] [error] [client 192.168.2.4] PHP Fatal error: Call
to a member function xpath() on a non-object in
/usr/share/wordpress/wp-content/plugins/import-html-pages/html-importer.php on
line 407, referer:
http://www.archivexparanormalstories.com/wp-admin/admin.php?import=html”
There is no clue as to what the problem is, what file was being operated on, and what caused the error. My only recourse is to feed the files in individually to identify the file that is causing the problem. At this point, I am forced to create the page by hand, using cut and paste. As this is happening frequently, this is causing quite a problem. The source file where the error occurred is available, should you want it.
Please note, I am an experienced PHP, html, and Perl programmer (just not with the WordPress API). If you could tell me exactly what is causing the problem, I can correct the old files appropriately.
You’re doing great work, I used earlier version of the html importer last year, after the first use, I ran into problems that we exchanged mails several time but the problem was unsolved. By mistake I came across development version of the plugin today, I followed your instructions as usual and all the works left undone after how many months were just uploaded at a click of button.
This tells me you are spending sleepless night working on perfecting the plugin. We are still gathering articles for my website, Hope to get stabilised and send you some thing for coffee (a promise).
Great plugin! Have anyone tried converting HTML pages with tags to video files? I’m converting HTML -> PHP but pages use tags to mp4 video files.
Any hint…. ?
Thank you…
Hi!
First of all I would like to say that this is a great plugin. Helps me a lot.
I have an issue with regards to language characters.
I`m from Norway and we have e.g. the letter ø. It seems like the parser stops at some point when this characters is found and leaves the imported page broken.
Is this issue allready supported or do I need to fix it at another end. Any advice?
Hi.
Can you take a look at the code below and see what that can be wrong with it. I suspect somethin with the stylesheet part messes things up. A sentence starting with P.mypar is displayed for the page and after that the page is broken. Is there something I haven`t configured the right way?
P.mypar {text-align: center}
{font-style: italic;size=small} {display: block}
TH {background-color:#FFFF66}
Serierenn 2
Serierenn 2
Tylldal IL Skigruppa.
13.02.13
Resultatliste G09Return
Plass
Navn
Klubb Tid
Horten,Brage Tylldal IL 06:49
Nystuen,Iver Tylldal IL 05:15
13.02.13 21:00:58 eTiming versjon 3.0 Emit as Lisensen tilhører: TYLLDAL IL
Hi, Tommy. Usually, when imported content gets cut off like that, it means your old database and your new one are using different character sets. Here’s a long article explaining the problem and how you might be able to fix it.
Hi Stephanie! Thanks so much for making this plugin! It’s a big bright ray of hope in my current situation. I’m trying to do a conversion of a Dreamweaver-created HTML site to WP and this utility has got it 90% of the way there :)
A quick note before I ask a question about the remaining 10%. Did you know your link to the HTML Importer on your code/wordpress/ page goes to the delicious page instead? Just wanted to fyi you on that.
Re my question, I found that the site I’m converting does not always have an HTML file in its directory structure. This causes the page structure the importer is creating to “skip” that part, resulting in a broken page structure.
Example: there are HTML files in directories 1 and subdirectory 1/1, but not in 1/2. But directory 1/2 has subdirectories 1/2/1 and 1/2/2 and they do have HTML files in them.
The page structure the importer creates has top parent 1 and child 1/1, then the structure breaks and you get top parents 1/2/1 and 1/2/2. Directory 1/2 is skipped because it has no HTML file, and the importer basically treats the next HTML file under the empty directory as a top parent.
I am working on a way to populate the empty directories with blank index files so I get a good import, but I wanted to ask if there’s an easy change I could make to the plugin instead? The basic case would be “if there’s a subdirectory, make a blank page even if it has no HTML file in it”.
Thanks again for making such a cool tool!
David
Hi, David. I keep meaning to write up a long guide to preparing a site for use with this importer, which would include things like seeding empty directories with dummy HTML files to force a parent page to be created.
But if you’re comfortable mucking around in the code, you can definitely adjust the importer to create pages for all the directories. (And I do mean all; this might create more than you really want.)
In html-importer.php, starting at line 292, replace your elseif block with this:
elseif(is_dir($path) && is_readable($path)) { if(!in_array($val, $this->skip)) { /* $createpage = array(); // get list of files in this directory only (checking children) $files = scandir($path); $exts = array(); foreach ($files as $file) { $ext = ''; $filename_parts = pathinfo($file); if (isset($filename_parts['extension'])) $ext = strtolower($filename_parts['extension']); /* $ext = strrchr($file,'.'); /**/ $ext = trim($ext,'.'); // dratted double dots if (!empty($ext)) $exts[] .= $ext; } // allowed extensions only, please. If there are files of the proper type, we should create a placeholder page $createpage = @array_intersect($exts, $this->allowed); // suppress warnings about not being an array if ( !empty($createpage) && is_post_type_hierarchical($options['type'])) { $this->get_post($path, true); } /**/ // create a parent page for all directories whether or not files with the allowed extensions are present if ( is_post_type_hierarchical($options['type'])) { $this->get_post($path, true); } // handle the files in this directory -- recurse! $this->get_files_from_directory($path); } }I think that should work.
Thank you so much for the quick response Stephanie! “Mucking around” exactly describes my approach to code at this stage :) I’ll give that a shot straightaway.
It’s fine if I get more empty pages than necessary to keep the structure.I have to review everything anyways so cleaning up extra blank pages is much less an issue than recreating the content structure by hand :)
I’ll let you know how things go!
David
Hi Stephanie. Sorry to report it didn’t work :( I’ll take this over to the support forums now per your suggestion to someone above.
Thanks so much for the quick response!
David
Hello,
Its a great piece of code. Seems to be working great.
I have a query though.
I want to import this specific link
http://judis.nic.in/supremecourt/imgst.aspx?filename=1180
The content is under text area, and the title of the post needs to be the values the values after the word “Petitioner” and before the word “date”.
Is it possible to do that here??
Hi Stephanie,
I have an HTML site and want to import all my html content to my subfolder into wordpress…
I have a question regarding importing images… for some reason importing content goes well, but when I look at my media… none gets imported??? How to go around this issue?
I am trying to import 1000 pages…. do you think i should just import one directory at a time to make things easier so it doesnt hang?
Lastly, for replacing internal links would it be possible to massively replace these internal links?
Well it appears I have learned the hard way. After 2 hours of selectively creating and pulling out custom post types, it appears your plugin does not support multiple page import from just one, am I correct? I would imagine others face this often though perhaps I am wrong. But I have multiple, one page markups that contain up to 50 what should be individual posts inside each. It would be very helpful if we could set a reference start point and end point via attribute to exist what would be each post. Thank you anyway for your work on this. Im sure its very helpful to some.
Taken from a comment you made in the official wordpress support forum for this plugin. Stephanie you wrote: “It would be technically possible to have the importer crawl URLs, but I’ve resisted building that feature because I don’t want to enable content thieves”
I just cant resist commenting on this because Stephanie you are truly a gifted talent with alot to offer. BUT we end users are apparently really missing out on what you really could offer. Do you think because you resist building a feature as part of a plugin, program, guide, etc that you are doing anything to stop content thieves? The answer is no. Absolutely not. They will just find another means. The only thing you ARE in fact doing is holding back features to which legitimate users could be taking advantage of. Its a shame. Its thinking like this that holds the world back as a whole. Just food for thought.
Well, that’s a bit melodramatic. You will note that the plugin, like WordPress, is GPL, and there’s nothing stopping anyone from creating a fork of it that does crawl remote websites. It just won’t be me.
Hi again Stephanie! I spoke to you about the HTML Import tool in the past and wanted to hop in with a quick perspective on how link crawling would have helped in my situation.
The site I tried it on was composed of over a thousand HTML pages, some of which had been obsoleted in the past by delinking. So in essence, anything with a current valid link in a menu was considered to be currently valid content. In that sense, crawling the menu links and creating a WordPress page structure to match would have been the ideal solution, as I would have avoided having to manually filter obsolete pages.
I understand your concern about content theft, but I’d like to point out that my usage wasn’t (and would never be) crawling remote websites from the front end. My use case for your tool was building WordPress page structures from a site in a locally available directory (even if the site ws remote, I would have been authorized directory access to it, and could have easily copied it down to my machine for the conversion).
So if the link crawling feature were restricted to HTML files accessible in local directories only, that *should* address the concerns about content scraping / site stealing.
Not that I’m trying to get you to do more work :) I don’t happen to have a need for that functionality at the present. I just wanted to put in my experience with that situation.
Thanks again for making such a great tool! It’s open source devs like you that save the butts of front-end people like us :)
Hi
I have the above website, created as a number of static HTMLpages with a lot of pictures. I used Frontpage.
I would like to convert to WordPress, and thought this plugin would be my rescue: Not having to manually copy/paste all the pages and content.
I have downloaded (using FileZilla) all the content to my Mac in this directory /Users/janmolgaard/Documents/molgaardsdk/ which I put into “Directory to import”
But I can’t make the plugin import the content :-(
Nothing happens….
I started with the official version, but have also tried the development version.
I select Import a directory of files, but I am not able to pick a directory, only a single file
What do I do wrong?
Hi, Jan. This is an old blog post; the plugin is not currently in beta.
Have you looked at the user guide?
Hi!
Thanks for Quick response.
Yes I have tried to follow the guide, even though it it’s for an older version.
The old and New site is on the same server.
I first tried to import directly just using the address on the server, but no import.
I then moved the files to my Mac and tried again, still no import.
I then tried with just the index.htm file. It was importen, but it couldn’t find the pictures.
In the Tags sektion, I just wrote BODY, and no values, thinking it was sufficient.
Hope you can help me
/Jan
I am building a clone of a eco-product site, and need to get the company’s 1000+ products into WordPress. I purchased a mass uploaded, which deleted the link in the first image tag it found in every uploaded file! I purchased another … and couldn’t even download. I then converted files to XML … except the “free” plugin wouldn’t handle images unless you bought the pro version for $99!!
Then I discovered this great little plugin. Takes the HTML page, and converts it to WP file. Brings in title from … and rightfully removes it from posted content. I love it!
Two things I would like: My site is divided into 15 directories, each with products inside. Whilst you can select a WP category within “HTML Import” to post to, it does mean you’ve got to FTP each directory of files to the server, then set the folder to look in / set category manually. Would be nice if the script could ‘read’ the temp folder, and select it’s own categories.
For example:
temp_folder/
aloevera/
aromatherapy/
bags/
…
..
.
The script would read the temp_folder, and see the 15 directories within. It would then use the folder name, (aloevera) and set the WP cat to that folder. Would then read all the files within that folder, and import them all.
So one button press, and multiple folders /files imported. (OK, so this may be a bit specialised, but might be an option others might use)
A real “plus” would be to read the first tag in HTML, and use this to set the Featured Image once said file had been uploaded to media gallery.
Just some ideas.
Hello Stephanie hope you are well And thank you so much for creating such an amazing plugin Html Import 2 for wordpress.
i am using post_tag for importing tags.
Now if i have these two lines with paragraph tags. for example
first
second
And than i create two custom fields to import both line of p tag with there values and using post_tag in custom field name but still i only import one tag from first html line,
So my question is how i import both html lines as a tag .I want to do this because in my situation both html paragraphs are on different lines of my html page.
https://wordpress.org/plugins/import-html-pages/
Best Regardss
Shahroz
Stephanie,
This plugin saved me so much time and money rebuilding sites!
I am looking for a place to donate to you, would you please provide a link?
Thanks,
-Eric
Thanks, Eric! There’s a PayPal link on the main plugin page.
I wanted to donate also, but I can’t find the Paypal link on the main plugin page.
It’s the third link just above the screenshots. Here you go!
Wish I’d have seen this – I have amended it to handle linked images. I also import from Dreamweaver and some of the regex was incorrect – siple enough to correct – just a space here and there that should have been omitted.
I also updated mine to merge content from more than one content area to create a single piece of content for the wordpress content area so it could have standard templates applied to it.
I’ve tested my version up to 4.9.4 and all works well.
The only thing I did’t update was the ability to handle multiple categories.
Happy to input / test your version if you like.