This was an independent study project done in early 2022 as part of the University of Washington iSchool‘s MLIS program.
In 2007, Anat Vernitski proposed a classification of intertextual relationships for humanities scholars studying fiction. To date, little work has been done to follow through on her proposed implementation of the scheme, which involved inviting humanities scholars to supplement library records through crowdsourcing. Displaying these relationships in library catalog records would make it easier for people to find similar books to those they’ve liked, or for writers to find prior art related to their ideas.
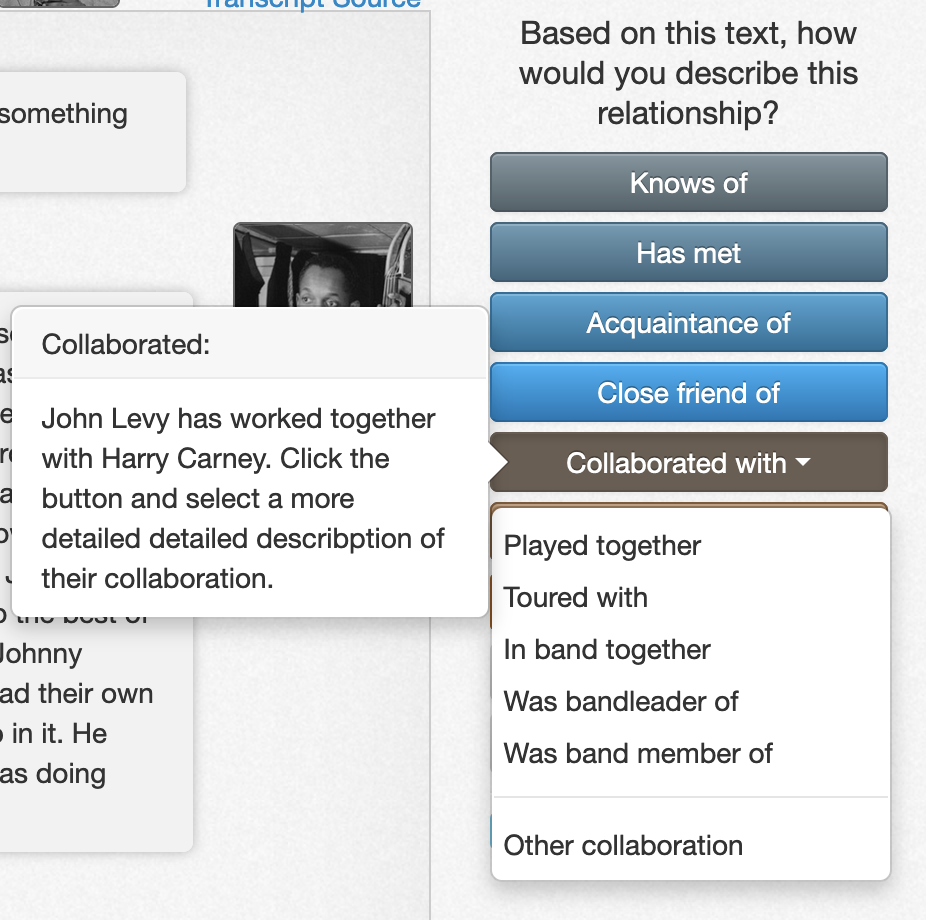 The Linked Data Lab’s LinkedJazz project has a tool called 52nd street where users review interview transcripts, selected by musician. The named entities (musicians, bands, venues) have already been identified, but software cannot identify the nature of the relationship between any two of those. The project presents a public web interface where users check the transcript and then choose the type of relationship from a menu: these two people were acquainted, they played together once, they played together in a band, they were in multiple bands together, they were friends, etc. These selections transform the basic hyperlink into a proper linked data entity relationship.
The Linked Data Lab’s LinkedJazz project has a tool called 52nd street where users review interview transcripts, selected by musician. The named entities (musicians, bands, venues) have already been identified, but software cannot identify the nature of the relationship between any two of those. The project presents a public web interface where users check the transcript and then choose the type of relationship from a menu: these two people were acquainted, they played together once, they played together in a band, they were in multiple bands together, they were friends, etc. These selections transform the basic hyperlink into a proper linked data entity relationship.
Initial Proposal
This independent study proposes using a process similar to 52nd Street’s to identify intertextual relationships between science fiction works using publicly available interviews and reviews from tor.com, io9, and Locus. To keep the scope of the project manageable, the named entity list will be drawn from Dr. Shaun Duke’s list of space operas by women/non-binary/trans authors. Additional data may be drawn from ISFDB, the SF Research Database, and the Historical Dictionary of Science Fiction.
With the interviews assembled into a text corpus, entities and relationships could be identified using SpaCy and corrected by users in Prodigy. The relationship choices will be drawn from Vernitski’s proposed classification (inspirations, direct quotes, retellings, etc.), and may be supplemented if additional relationship types are identified during the review process.
The ultimate goal would be to incorporate these relationships into catalog records so that searchers could trace links of inspiration and allusion in fiction in the same way they do citation chains in academic publications.
Implementation
I discovered that io9’s new owners have mostly eliminated the tagging system that would have let me locate the interviews. I switched to SF Site instead. Its markup is archaic, but consistent enough to be scraped with a little extra logic.
After reviewing PoolParty (a preferred tool at the UW iSchool), Voyant RezoViz, NLTK, SciKit-Learn, Prodigy, UBIAI, brat, doccano, and INCEpTION, I settled on Prodigy as the best choice for user annotation (particularly because of its forthcoming Teams version). The Sandia National Labs report on the state of the art in relationship extraction tools was extremely helpful in narrowing down the choices.
I was optimistic after my initial literature review; I thought identifying the direction of relationships would be a problem, when in fact finding the relationship at all has been difficult. Prequels, sequels, and series are too fine-grained for the software to distinguish, so I have consolidated these choices into one, Series. I have eliminated all questions of directionality.
The final set of relationship choices I used in spaCy and Prodigy is: Inspiration, Allusion, Quotation, Series, and Collection.
Some authors, when asked to cite inspiration for their work, either give a person’s without specifying the work they have in mind, or referring to the person’s entire body of work. In some situations, it is assumed that the reader will understand which work is being referenced. For example, a solarpunk author who cites Ursula K. LeGuin as their inspiration is almost certainly referring to The Word for World Is Forest, or the Hainish Cycle series as a whole. In other cases, the reference is less clear. A space opera writer citing C.J. Cherryh as an inspiration might be referencing either or both of her long-running series in that subgenre, one involving contact with alien civilizations and one not.
Since the ultimate goal of this project is to enhance library catalog records, future implementation questions hinge on the capabilities of the catalog software. Citing an author without specifying a work is at least possible in catalog records using authority files and unique identifiers. Citing a series as a source of inspiration, however, presents a problem: how should this be recorded in the catalog? Series authority records do exist, but library ILSs seldom make use of them in a way that is useful to fiction readers.
Limitations and Challenges
The Sandia Labs report notes that these tools are all quite limited: “Though entity extraction is performed with a fair amount of accuracy, relationship extraction remains an ongoing elementary stage issue. As of now, current tools can recognize two entities within the same sentence are related, which is both trivial and not necessarily true. Context information from the text is not understood, therefore meaning and relationships are lost. Relationship extraction remains in early stages and, based on literature, has been mostly abandoned for new ideas.”
This suggests possible avenues for research into new relationship extraction models, such as chunking documents by paragraph or even document instead of sentence. Relationships might also be inferred through related concepts. If an entity-concept relationship can be identified in a sentence, a model could infer relationships, however tenuous, between all other entities linked to the same concepts within the document. The recently-revamped BookNLP project might address some of these limitations, but was released only days before the end of my study and I did not get a chance to experiment with it.
In the introductory tutorials I reviewed, entity names are generally assumed to be unique. Yet another layer of processing would be required to associate names with their pseudonyms and transliterations under a single ID through an authority file. SpaCy’s KnowlegeBase and EntityLinker components may be useful for this sort of linking. Pattuelli, et al. describe their method of linking artist names in LinkedJazz in their 2013 Code4Lib article. Future work on this project would need to incorporate this step.
SpaCy’s default settings proved hit and miss on some entity matches that should have been straightforward. For example, in this dual interview with Arkady Martine and Drew Williams, the works that inspired theirs are discussed explicitly:
What are some books (or movies or games) that inspired this series, directly or indirectly?
AM: CJ Cherryh’s Foreigner series is a pretty direct inspiration for the Teixcalaan books—I definitely wanted to write, in some ways, a response to Foreigner. But most of the inspiration for A Memory Called Empire comes straight out of Byzantine and Armenian history.
DW: I mean, Star Wars, for sure, and Joss Whedon’s Firefly; also, just in general, any time I’m writing space-based sci-fi, I try to keep Douglas Adams’s The Hitchhiker’s Guide in the back of my mind, just because of how well Adams gets across the notion of the vastness of space, of just how big a galaxy with multiple space-faring races would be.
These sentences should be prime candidates for my relationship extraction experiment. However, spaCy failed to recognize the Foreigner and Teixcalaan series and The Hitchhiker’s Guide as works of art, and misfiled CJ Cherryh and Firefly as organizations. (Manually adding “to the Galaxy” to complete the title of The Hitchhiker’s Guide did not help.) Furthermore, since the two authors being interviewed are referred to using their initials throughout the Q&A, the model failed to recognize them as entities in that portion of the text. Expanding their initials to their full names corrected this, suggesting that doing so programmatically for interviews would be an essential step, since the relationship extraction model relies on proximity.

An interview with two people might be expected to challenge the relationship extractor, but this fails to even find all the relevant named entities needed to establish the relationships. Ward’s statement that “entity extraction is performed with a fair amount of accuracy” is therefore shown to be overly optimistic, at least with regard to works of art.
Future Research
It is clear that rules specific to the types of documents being processed would have to be established at the outset of a large project. For an unclassified text corpus (or the open web), this might involve running a classifier early in the pipeline so that specific rules could be applied to different document types. For example, interviews should go through a coreference resolution step that not only resolves pronouns, but also associates people’s initials with their full names. However, this would have to be a feedback step: if done before the entities are labeled, “AM” would probably be assumed to be a time of day, and would be recognized as a set of a person’s initials only after “Arkady Martine” had been established as a relevant entity. Only after the coreferences have been resolved would it make sense to move on to the correction step, where spaCy’s predictions are compared to the known entity list.
There are numerous coreference models available. This article describes using spaCy with the HuggingFace Neuralcoref model on This American Life transcripts, which is very similar to this project’s corpus. (Future work might include processing the interviews not only to resolve coreferences, but to tag spans of text by speaker, as Ira Glass is identified in this example, and find relationships using that tagged chunk of speech instead of individual sentences.)
The spaCy pipeline steps would be something like:
- Document classification (interview, review, news article, etc.)
- Entity recognition (“Arkady Martine” = person, “A Memory Called Empire” = work_of_art)
- Coreference resolution and expansion of initials (pronouns; “AM” = “Arkady Martine”)
- Repeat entity recognition (step 2) on expanded coreferences
- Run rule-based matching using list of names and works of art to correct annotations
The project would then move to Prodigy to have users annotate relationships and correct errors.
Given that UW’s ten-week quarters are very short, that I spent the first four weeks learning the basics of Python, and that I lost a week to COVID-19 in the middle of the quarter, I’m pleased that I was able to get close to my original goal. I was able to use SpaCy to tag entity relationships in my little text corpus, and I was just a few cleanup steps away from presenting the tagged documents and relationship choices to users in Prodigy for corrections and additions. I may return to this project over the summer, if time permits, to experiment with the coreference tools and complete the Prodigy setup.
(This is a highly condensed version of my reports for the independent study. Feel free to contact me for copies of the longer documents and bibliography.)


